#2PDF RAG를 처음부터 만들어보면서 마주친 것들
임베딩 호출 최적화, 청킹 전략 비교, 한국어 임베딩 분포, 환각 방지 프롬프트, 멀티모달 PDF, 평가 체계 전환까지. RAG 한 사이클을 직접 굴리며 부딪힌 의사결정들.
들어가기 전에
PDF 문서 기반 RAG 챗봇을 처음부터 끝까지 한 사이클 굴려본 기록이다. 단순한 RAG 튜토리얼은 잘 정리된 게 많지만, 막상 실제 문서를 던져 넣으면 그때부터 의사결정의 연속이 시작된다. 그중에서 시간을 잡아먹은 트러블슈팅과 그 결정의 근거를 정리한다.
깊게 다룬 두 가지 횡단 주제(평가의 역설, 인프라 함정)는 4편과 5편에서 따로 풀었다.
임베딩 호출이 너무 느렸다 — 개별 vs 리스트
처음엔 청크 하나하나를 따로 임베딩하는 코드였다. 1,000페이지짜리 보고서를 올리면 청킹보다 임베딩 HTTP 호출이 병목이었다.
Ollama API 문서를 다시 들여다보다가 발견한 게 있다. prompt 파라미터가 문자열 하나가 아니라 배열도 받는다. 한 번의 HTTP 호출로 여러 청크를 한꺼번에 임베딩할 수 있다는 뜻.
8개 PDF, 총 1,603페이지로 비교 실험을 돌렸다.
| 문서 | 페이지 | 개별 호출 | 리스트 호출 | 차이 |
|---|---|---|---|---|
| docuflow_test | 12 | 3.31s | 2.56s | +29.3% |
| 창업지원사업 통합공고문 | 105 | 25.25s | 15.53s | +62.6% |
| 행정안전백서 | 224 | 43.38s | 25.31s | +71.4% |
| 한국인의 역량 | 405 | 88.75s | 51.43s | +72.5% |
평균 63.5% 빠름. 페이지 수가 늘수록 차이가 커진다. HTTP 왕복 비용이 압도적이라는 뜻. 여기서 하나 배웠다 — API 문서의 입력 형식을 한 줄 한 줄 다시 본다. 평소 무심코 넘기던 곳에 자주 이런 게 숨어 있다.
청킹 전략 — 12개 config 비교, 4개로 좁히기
다음 의사결정. 청크 크기, 오버랩, splitter 종류. 흔한 디폴트(chunk_size=1000, overlap=200)를 쓰면 그럭저럭 동작하지만, 그 값이 우리 데이터에 맞는지는 별개의 이야기다.
비교 테스트를 위해 전용 비교 UI(/compare) 를 만들었다. 한 PDF를 올리면 N개의 청킹 설정으로 동시에 임베딩하고, 같은 질문으로 각 설정의 검색 결과를 나란히 보여주는 화면. 처음엔 splitter 2종 × chunk_size 3종 × overlap 2종 = 12개 로 다 돌려본 뒤, 의미 있는 차이를 보이는 4개로 좁혔다.
| # | Splitter | chunk_size | chunk_overlap |
|---|---|---|---|
| 1 | recursive | 256 | 25 |
| 2 | recursive | 512 | 50 |
| 3 | recursive | 1024 | 100 |
| 4 | nltk | 1000 | 100 |
4개 문서 × 4개 config × 다양한 질문 — 결론은 "문서 종류에 따라 최적값이 다르다". 단락 위주의 정책 보고서는 chunk_size 1024가 좋고, 표가 많이 들어간 공고문은 작게 잘라야 표 한 셀이 다른 청크로 흩어지지 않는다. 정답이 한 개가 아니다. 디폴트로 시작하되, 타겟 문서로 한 번은 비교 실험을 돌리는 것이 RAG 첫 의사결정.
한국어 임베딩의 분포 — nomic 에서 bge-m3 로
이게 가장 결정적인 의사결정 중 하나였다.
처음엔 nomic-embed-text (768차원)를 썼다. 영어 RAG 튜토리얼의 단골 모델. 잘 동작했다 — 까지는 좋았는데, threshold=0.5 이상만 통과시키는 필터링이 거의 무의미해지는 현상이 발견됐다. 한국어 문서에서 무관한 질문을 던져도 유사도가 0.85 이상이 나오는 식.
원인을 들여다보니 모델별 한국어 유사도 분포가 완전히 다르다. nomic은 모든 한국어 텍스트를 0.65~0.87의 좁은 범위에 몰아넣는다. "관련/비관련" 구분 자체가 흐릿했다.
bge-m3(BAAI, 다국어 특화 1024차원)로 교체했더니 분포가 0.39~0.64로 풀렸고, threshold 필터링이 비로소 의미를 갖기 시작했다. 같은 질문에 대한 검색 품질이 눈에 띄게 올라간 건 덤.
임베딩 모델 분포 차이는 평가 체계 전반에 영향을 주는 횡단 주제라, 4편 — RAG 평가의 역설에서 따로 자세히 분석했다.
환각 방지 — 시스템 프롬프트 V1 → V2
검색 품질이 잡히고 나니 다음 문제가 보였다. 문서에 없는 질문을 받으면 LLM이 그럴듯하게 지어낸다.
V1 프롬프트(제약 없음) vs V2 프롬프트(근거 기반)로 같은 질문 셋을 돌려봤다.
| 질문 유형 | V1 응답 | V2 응답 |
|---|---|---|
| 문서에 있는 질문 (Pro 플랜 금액) | 정답이지만 근거 없음 | 정답 + 문서 섹션 인용 |
| 문서에 없는 질문 (2025 매출액) | 분기별 매출 6,000만 달러로 추론 (환각) | "문서에서 확인할 수 없다" 거부 |
| 무관한 질문 (프로야구 우승팀) | 거부하면서 서비스 설명을 길게 늘어놓음 | 짧게 거부 |
V2의 골자는 단순했다.
- 답은 반드시 제공된 컨텍스트에서만 가져와라.
- 컨텍스트에 없으면 "문서에서 확인할 수 없습니다" 라고 답해라.
- 답할 때 어느 문서·섹션에서 가져왔는지 인용해라.
- 무관한 질문에는 짧게 거부해라.이걸 시스템 프롬프트의 한 섹션으로 못 박는 것만으로 환각이 절반 이상 줄었다. 모델 바꾸지 않고도 품질이 올라가는 가장 싼 수단이 프롬프트.
멀티모달 PDF — 텍스트만으론 부족했다
여기까지가 텍스트 RAG 베이스라인. 그런데 실제 보고서·논문 PDF를 올려보니 본문 텍스트만으로는 검색이 안 되는 질문이 한 무더기였다. 표에 들어 있는 수치, 차트의 비교, 인포그래픽 안의 텍스트 등.
파이프라인을 텍스트 + 표 + 이미지로 확장했다.
| 추출 대상 | 도구 | 처리 |
|---|---|---|
| 텍스트 | pdfplumber | 페이지별 텍스트 추출 |
| 표 | pdfplumber | 마크다운 테이블로 변환, 별도 청크 |
| 이미지 | PyMuPDF | GPT-4o-mini Vision으로 자연어 설명 생성 → 텍스트로 임베딩 |
여기서 자잘한 트러블슈팅이 두 번 있었다.
페이지 분할 표 자동 병합
보고서의 큰 표는 페이지 경계에서 잘려서 들어온다. 그대로 두면 표 절반이 청크 A에, 나머지 반이 청크 B에 들어간다. 검색 시 둘 중 하나만 잡히면 답변이 반쪽이 된다. 두 가지 케이스로 자동 병합했다.
- 케이스 1: 동일 헤더가 양 페이지에 반복 → 헤더 한 번만 두고 행만 이어 붙이기
- 케이스 2: 헤더 없이 데이터만 이어지는 경우 → 컬럼 수 동일 + 첫 셀이 숫자면 동일 표로 가정
차트는 끝까지 포기
Vision API에 차트 이미지를 던져 봤지만, 수치 자체를 매번 다르게 읽었다. 정답이 2,791억인 막대 차트에서 239억 / 393억 / 182억이 나오는 식. 모델 한계라 깔끔히 받아들였고, 그 대신 본문에 같은 수치가 있을 때 거기서 가져오게 프롬프트로 유도하는 방향으로 갔다.
차트 환각의 자세한 분석과 "정직한 답변" 설계는 4편 — RAG 평가의 역설 첫 에피소드에 정리했다.
평가 체계로 — Playwright E2E → LangSmith
이 분기점이 가장 중요했다. 평가 체계가 없으면 그 다음 어떤 개선도 미신이 된다.
처음엔 Playwright로 E2E 자동화를 짰다. 2개 문서 × 6가지 변인(Top-K, Threshold, Prompt, Re-ranking, Query Rewriting, 복합 최적조합) = 총 54건 실험. 브라우저를 띄워 질문을 하나씩 던지고 답을 채점하는 방식.
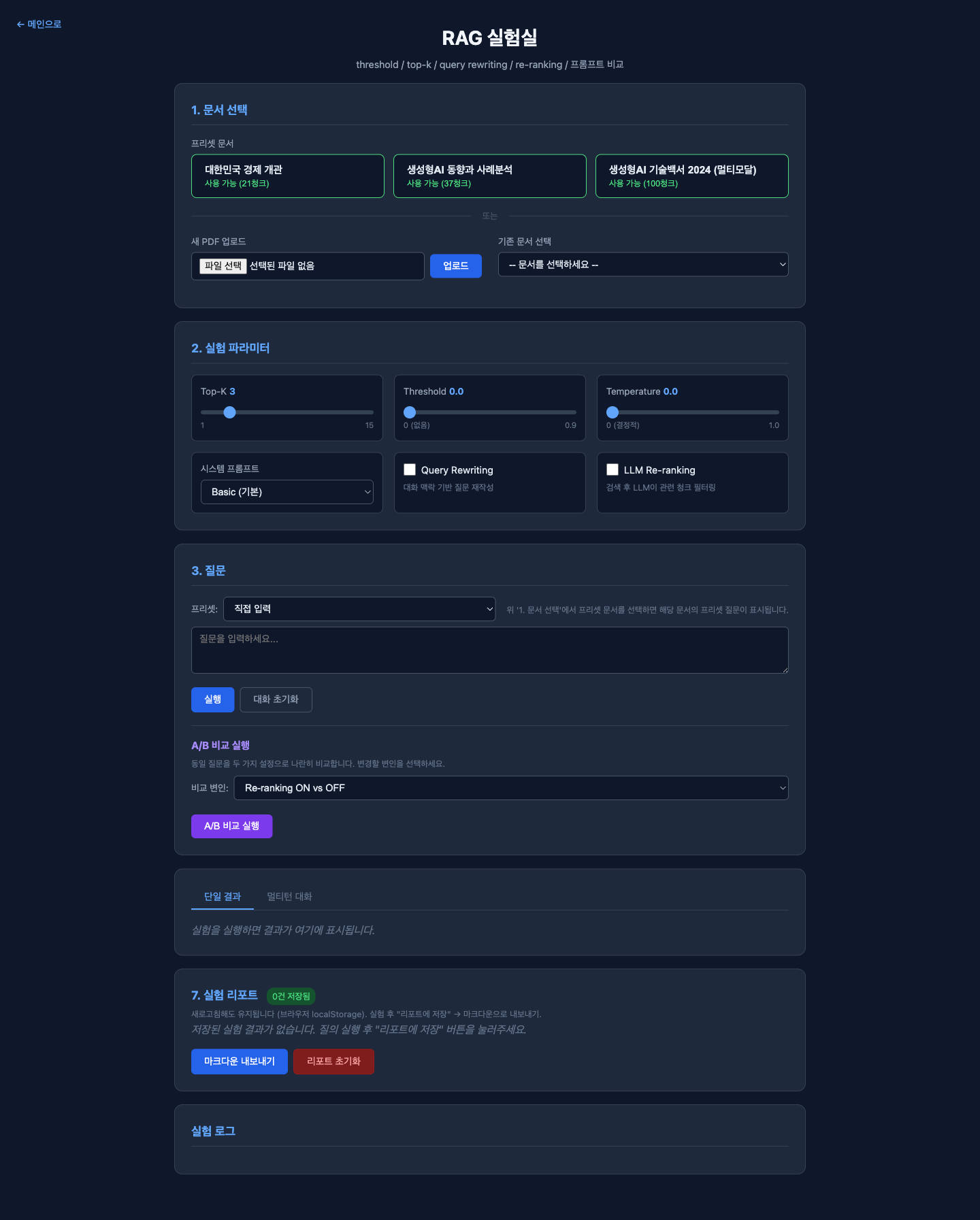 로컬에 따로 만든
로컬에 따로 만든 /experiment UI. 위 6가지 변인을 하나씩 바꿔가며 같은 질문을 돌릴 수 있게 했다.
이걸로 결론 몇 개를 뽑았다.
- Top-K: 문서별 최적값이 다르다. 어떤 문서는 K=3, 어떤 문서는 K=7.
- Threshold: 0.7 이상은 정답까지 같이 잘려나간다. 0.3~0.5 권장.
- 시스템 프롬프트: 수치 중심 문서는 strict, 개념 중심 문서는 basic이 더 좋음.
- 리랭킹: 노이즈 제거에 효과적이지만 과잉 필터링 위험.
- Query Rewriting: 단발 질문에선 효과 없음. 멀티턴에서만 의미.
그런데 Playwright E2E의 한계가 슬슬 보였다 — 느리고, 트레이싱이 빈약했다. 검색 결과가 좋아진 건지 LLM 답변이 좋아진 건지 분리해서 보기 힘들었다. 그래서 LangSmith 기반 정량 평가로 전환했다.
- 파이프라인 전 구간 (검색 → 프롬프트 → LLM 응답) 트레이싱
- 자동 채점 평가기 4종:
correctness— A·C유형 정답 일치 (LLM-as-Judge)faithfulness— 컨텍스트 근거 충실도 (LLM-as-Judge)rejection_accuracy— C유형 거부 성공 (규칙 기반)table_retrieval— 표 질문에서 마크다운 표가 검색됐는지 (규칙 기반)
LangSmith로 옮긴 뒤로 한 실험을 돌리고 결과 분석하는 사이클이 분 단위로 줄었다. 정량 평가가 자리잡으니 비로소 "고도화" 라는 단어가 의미 있게 들리기 시작.
평가 체계 자체가 만들어내는 역설들 — 올바른 거부가 0점을 받거나, 같은 설정 두 번 돌렸을 때 점수가 뒤집히는 — 은 4편에 따로 묶었다.
멀티모달 RAG 5회 실험 — 변수 1개씩 격리
평가 체계 위에서 멀티모달 RAG에 대해 변수 1개만 바꾸는 실험을 5회 반복했다 (생성형AI 기술백서, 표 34개·차트 8개, QA 15개).
| # | 실험 | 설정 | 목적 |
|---|---|---|---|
| 1 | k3-basic (A) | top_k=3, basic, rerank OFF | 베이스라인 |
| 2 | k3-basic (B) | 동일 설정, 다른 실행자 | LLM 비결정성 측정 |
| 3 | k5-strict-rerank | top_k=5, strict, rerank ON | rerank 효과 |
| 4 | k5-strict | top_k=5, strict, rerank OFF | strict 단독 효과 |
| 5 | k5-strict + 표 병합 | + 페이지 분할 표 병합 | 병합 효과 |
| 지표 | k3-basic (A) | k3-basic (B) | k5-strict-rerank | k5-strict | k5-strict + 병합 |
|---|---|---|---|---|---|
| correctness | 0.50 | 0.80 | 0.65 | 0.60 | 0.80 |
| faithfulness | 0.667 | 0.667 | 0.773 | 0.667 | 0.70 |
| rejection_accuracy | 0.80 | 0.40 | 0.40 | 0.60 | 0.00 |
| table_retrieval | 0.889 | 0.889 | 0.667 | 0.889 | 0.889 |
여기서 세 가지 큰 발견이 있었다.
1. 검색 개선 ≠ 답변 개선. 표 병합으로 정답이 들어 있는 컨텍스트가 검색됐는데도 LLM이 표의 최대값을 잘못 읽어 답변이 틀린 케이스가 반복됐다. "검색에 정답 청크가 들어왔는가" 와 "LLM이 그 청크로 올바른 답을 만들었는가" 는 분리해서 측정해야 한다는 게 분명해졌다.
2. 1회 실행 결과를 확정 짓지 말 것. 같은 k3-basic 설정인데 실행 시점에 따라 correctness 0.50 vs 0.80, rejection_accuracy 0.80 vs 0.40. LLM 비결정성 + 소규모 데이터셋(15개) → 노이즈가 시그널보다 크다. 결론을 내리기 전에 반복 실험과 평균이 필수.
3. 차트는 안 풀린다. Vision API가 같은 차트를 매번 다르게 읽는다. 모델·프롬프트를 바꿔도 한계. 결론은 "못 읽는 것을 어떻게 다룰 것인가" 로 무게 중심을 옮기는 것. (이 설계는 4편 첫 에피소드에서 자세히.)
정리하면서
한 사이클 굴려보고 박힌 것을 한 줄씩 적으면 이렇다.
- RAG 품질의 60%는 청킹·임베딩에서 결정된다. 모델·프롬프트는 그 위에 얹는 마무리.
- 평가 체계가 없으면 어떤 고도화도 미신. LangSmith든 자체 채점이든, 수치로 분리해서 비교할 수 있는 환경을 먼저 만들고 그 다음에 변수를 바꿔라.
- 검색이 맞아도 답변이 틀릴 수 있다. 두 축을 분리해서 측정하지 않으면 어디서 망가졌는지 모른다.
그리고 가장 큰 마인드셋 변화는 "잘 되게 만들기" 에서 "잘 되고 있는지 알게 만들기" 로 질문이 옮겨간 것.
다음 편
다음은 영역을 한 번 더 넓힌다 — 영상·음성 입력.
- 3편 — 영상에서 자연어 검색되는 시스템을 만들어보면서 마주친 것들 영상 → STT → 비전 → 타임스탬프 검색 파이프라인. 모델 교체 3건, WER → CER 전환, 평가 LLM의 "0.7 천장", 24분 영상을 1분 10초에 처리하기.
프론트엔드 6년차 개발자가 PI Lab에서 AI 엔지니어링 8주 과정을 수료하며 정리한 기록입니다. 매일 Cursor·Claude로 바이브코딩하면서도 머신러닝 안쪽은 잘 몰랐던 개발자가, AI 시스템을 본격적으로 들여다본 회고입니다.