#3영상에서 자연어 검색되는 시스템을 만들어보면서 마주친 것들
STT·비전·임베딩 모델 교체 3건, WER→CER 전환, 평가 LLM의 '0.7 천장', 집중 실험 10회, 24분 영상을 1분 10초로 줄인 병렬화. 영상 RAG에서 부딪힌 의사결정들.
들어가기 전에
영상·음성 입력을 받아서 자연어로 검색되는 시스템을 한 사이클 굴려본 기록이다. PDF RAG는 2편에서 다뤘고, 이번은 입력이 멀티미디어로 바뀌면서 새로 마주친 것들 — STT, 비전, 타임스탬프 검색, 그리고 그 사이에서 부딪힌 의사결정들이다.
평가 체계와 인프라 함정들은 4편·5편에서 따로 깊이 다뤘다.
파이프라인 개요
[영상 업로드]
→ ffmpeg으로 오디오 추출
→ faster-whisper STT 전사 + 타임스탬프
→ 30초 윈도우 청킹
→ bge-m3 임베딩
→ Supabase에 (text, start_time, end_time, embedding) 저장
[질문]
→ 임베딩 → pgvector 코사인 유사도 검색
→ 시스템 프롬프트 + 컨텍스트(타임스탬프 포함) → LLM
→ "1분 23초 부근에서 ..." 같은 답변핵심은 타임스탬프를 끝까지 보존하는 것. 청크에 시간 정보가 같이 붙어 있어야 답변에서 영상 특정 구간을 가리킬 수 있다. STT 출력의 segment 단위 타임스탬프를 청킹 단계까지 끌고 가는 구조를 잡았다.
![24분짜리 뉴스 영상에 대한 QA 답변 화면 — 답변 첫머리에 [01:10] 타임스탬프가 찍혀 있고, 우측 패널에는 근거 타임스탬프 목록이, 중앙 전사 세그먼트에는 STT 텍스트와 Vision 설명(📷)이 각 타임레인지 옆에 나란히 붙어 있다](/static/sprint3-multimodal/qa-answer-timestamps.png) 답변
답변 [01:10] … 30대 젊은이들입니다. → 같은 타임스탬프가 전사 세그먼트에서 그대로 하이라이트되는 구조. 우측엔 근거 타임스탬프 목록, 중앙 전사에는 STT·Vision(📷)이 한 세그먼트에 같이 묶여 있다.
모델 교체 3건 — 한국어 미지원 모델 하나가 파이프라인 전체를 무력화한다
가장 결정적인 트러블슈팅 묶음이었다. 세 모델을 동시에 갈았다.
STT — whisper small → whisper large-v3-turbo
처음 쓴 faster-whisper small은 한국어 전사 정확도가 부족했다. WER 평균 0.3~0.4 — 단어 3~4개 중 1개가 틀렸다. 검색 단계에서 타임스탬프는 맞아도 키워드가 어긋나, 검색된 청크가 "전혀 다른 말"이 됐다.
large-v3-turbo로 교체. 같은 정확도의 large-v3 대비 절반 리소스, 2~3배 빠름. WER이 0.15~0.25로 떨어졌다.
| 영상 | small WER | large-v3-turbo WER | 개선 |
|---|---|---|---|
| 안될과학 | 0.148 | 0.128 | 13% ↓ |
| 팩트체크 | 0.311 | 0.258 | 17% ↓ |
| 인터뷰 숏츠 | 0.418 | 0.264 | 37% ↓ |
| 생활의 달인 | 0.322 | 0.288 | 11% ↓ |
발화가 명확한 영상(안될과학)은 차이가 작고, 음성이 겹치는 인터뷰에선 차이가 크다. 모델 교체의 ROI는 가장 어려운 케이스에서 측정해야 한다.
Vision — moondream → gemma3
비전 모델로 처음 쓴 moondream (1B). 영어 중심 학습이라 한국어 화면 분석이 거의 안 됐다.
moondream (1B) 출력 예시:
구간 0:00~0:32 → "확인에서 거리를 변환할 수 있다."
구간 0:32~1:05 → "프레임"뭔 말인지 모를 답이 나온다. 모델 자체가 한국어 프롬프트·자막을 처리하지 못한 결과.
gemma3 (Google, 12B, 140+ 언어 지원)로 교체.
gemma3 (12B) 출력 예시 (같은 구간):
0:00~0:32 → "SBS에서 제작한 인터뷰 영상의 한 장면. 밝은 나무 소재의 벽면과
의자들이 보이는 공간에서 인터뷰 대상자인 젊은 남성이 카메라를 응시."
0:32~1:05 → "테이블 위에 쌀과 쌀 씻는 컵. 화면 우측에 금고. 테이블 옆에
전화기, 계산대 등의 사무용품."화면의 인물·장소·자막·UI 요소를 구체적으로 묘사한다. 비로소 사용 가능한 정보가 됐다.
Embedding — nomic-embed-text → bge-m3
2편에서도 같은 결정을 내렸던 부분. 한국어 유사도 분포 문제. nomic은 한국어를 0.65~0.87 범위에 압축해 무관한 질문도 0.88로 나오는 식. bge-m3로 교체하면서 분포가 0.39~0.64로 풀렸다.
임베딩 모델별 분포 차이는 4편 — RAG 평가의 역설 에피소드 2에서 자세한 수치와 함께 분석했다.
한 줄 교훈
이 세 교체를 거치면서 박힌 감각.
"한국어 미지원 모델 하나가 파이프라인 전체를 무력화한다."
임베딩이 한국어를 못 하면 검색이 실패하고, 검색이 실패하면 LLM이 아무리 좋아도 답변이 안 나온다. 비전이 한국어를 못 하면 프레임 분석 전체가 노이즈가 되어 검색 인덱스를 오염시킨다. 약한 고리 하나를 그대로 두면 다른 모든 강화가 무의미해진다.
WER → CER — 한국어 띄어쓰기가 평가를 왜곡한다
전사 품질을 측정하다가 발견한 함정. WER(Word Error Rate)이 한국어에서 신뢰하기 어렵다.
ref: "소비해 온"
hyp: "소비해온"
→ WER 계산 시: 단어 2개 중 2개 틀린 것으로 카운트전사가 의미상 100% 맞아도 띄어쓰기 한 칸 차이로 WER이 폭주한다. 영어는 단어 사이 공백이 명확해서 WER이 잘 작동하지만, 한국어는 띄어쓰기 자체가 유연한 영역이라 단어 단위 평가가 왜곡된다.
해결: CER(Character Error Rate)로 전환 + 전처리에서 문장부호 제거.
| 영상 | WER (전처리 전) | CER (전처리 후) | 개선 |
|---|---|---|---|
| 안될과학 | 0.128 | 0.022 | 85% ↓ |
| 팩트체크 | 0.258 | 0.107 | 58% ↓ |
| 인터뷰 숏츠 | 0.264 | 0.068 | 74% ↓ |
| 생활의 달인 | 0.288 | 0.083 | 71% ↓ |
평가 지표가 "측정 대상에 적합한가" 를 한 번 더 묻는 게 중요하다는 사례.
A·B·C 유형 평가 분리 — "올바른 거부"가 0점을 받는 역설
평가 함수를 짜다가 마주친 첫 번째 큰 함정. 질문 셋을 A·B·C 세 유형으로 나누고 LLM-as-Judge로 채점하는데, C유형(영상에 답이 없는 질문)에서 정직한 거부가 0점으로 나오는 현상.
질문 (C유형): 쿠팡의 2025년 연간 매출액은?
답변 A: "해당 영상에서는 언급되지 않습니다." → answer_relevance = 0.0
답변 B: "약 25조 원입니다." (환각) → answer_relevance = 0.8올바른 행동이 벌점을 받고 환각이 상을 받는다. 평가 함수가 "질문에 답하는 정도"를 측정하는 구조라서, 거부 응답은 구조적으로 낮은 점수를 받는다.
해결: 유형별로 평가 도구를 분리.
| 유형 | 평가 도구 | 이유 |
|---|---|---|
| A·B (답이 있는 질문) | answer_relevance (LLM-as-Judge) | 기존대로 |
| C (답이 없는 질문) | rejection_rate (패턴 매칭) | "확인되지 않습니다" 류 응답이면 1.0 |
평균도 Rel.(A/B) + Rej.(C) 로 분리 집계해서, 한 지표가 다른 유형을 잘못 측정하지 않도록 했다.
이 역설은 RAGAS 같은 외부 평가 프레임워크에서도 동일하게 나타나는 구조적 문제다. 4편 에피소드 3에서 더 깊이 분석했다.
집중 실험 10회 — 한 영상에 한 변수만 바꾸기
여기서 진짜 학습이 시작됐다. fact_check.mp4 한 영상 + 9개 프리셋 질문(A 3개·B 3개·C 3개)으로 한 번에 한 변수만 바꾸는 실험을 10회 반복했다.
| Run | 변경점 | Embedding | Chat | threshold | Rel_AB | Rej_C | Gnd | Prec |
|---|---|---|---|---|---|---|---|---|
| 2 | Baseline | nomic | llama3.1 | 0.5 | 0.633 | 1.0 | 0.700 | 0.556 |
| 3 | 임베딩 교체 | bge-m3 | llama3.1 | 0.5 | 0.700 | 1.0 | 0.700 | 0.333 |
| 4 | 프롬프트 v2 ❌ | bge-m3 | llama3.1 | 0.5 | 0.667 | 1.0 | 0.700 | 0.167 |
| 5 | threshold 완화 | bge-m3 | llama3.1 | 0.3 | 0.600 | 1.0 | 0.700 | 0.500 |
| 6 | Chat 교체 | bge-m3 | gemma3 | 0.5 | 0.733 | 1.0 | 0.578 | 0.389 |
| 7 | th + gemma3 | bge-m3 | gemma3 | 0.3 | 0.783 | 1.0 | 0.544 | 0.417 |
| 8 | OpenAI 전환 | emb-3-small | gpt-4o | 0.5 | 0.167 | 1.0 | 0.778 | 0.000 |
| 9 | OpenAI th 완화 | emb-3-small | gpt-4o | 0.3 | 0.617 | 1.0 | 0.556 | 0.222 |
| 10 | OpenAI th=0.2 | emb-3-small | gpt-4o | 0.2 | 0.617 | 1.0 | 0.333 | 0.250 |
이 실험에서 발견한 것 네 가지.
1. 프롬프트 v2 실패 (Run 4). llama3.1(8B)에 "거부 우선 규칙·번호 매기기·섹션 분리" 같은 구조화 프롬프트를 추가했더니 Precision이 0.333 → 0.167로 더 악화. 소형 모델에서는 "더 자세한 프롬프트" ≠ "더 좋은 결과" — 복잡한 지시가 오히려 답변 생성을 방해했다. v1으로 롤백.
2. Chat 모델 교체의 트레이드오프 (Run 6, 7). gemma3로 바꿨더니 Relevance는 로컬 최고 0.783까지 올렸지만 Groundedness가 0.544로 하락. gemma3는 세그먼트를 풍부하게 활용하지만 세그먼트에 없는 추론을 덧붙이는 경향이 강했다. Relevance와 Groundedness는 로컬 모델 조합으론 동시 달성 불가 라는 구조적 한계를 확인.
3. OpenAI 전환의 역설 (Run 8). GPT-4o는 좋은 컨텍스트만 주면 Gnd=1.0 + Rel=1.0을 동시에 달성하는데, text-embedding-3-small이 한국어를 0.22~0.52 범위에 압축해서 threshold=0.5에서 9개 중 8개가 0건 검색됐다. threshold를 0.2까지 내려도 "뉴스룸에서 뵙겠습니다" 같은 2초짜리 클로징 멘트가 유입되는 구조적 문제. 좋은 LLM도 임베딩이 발목 잡으면 무력.
4. 4지표 동시 달성은 로컬 조합으론 불가능. 이론적 최적은 bge-m3 (한국어 임베딩 잘함) + GPT-4o (답변 잘함) 혼합 인데, 기존 PROVIDER=local/openai 2분법 아키텍처로는 그 조합이 안 됐다. 이게 후반의 PROVIDER=deployment 신설로 이어졌다.
집중 실험의 가장 큰 교훈: "이론적 최적 조합"은 의외로 단순한데, 그걸 코드 아키텍처가 막고 있는 경우가 많다. 모델만 바꿔보지 말고 분기 구조 자체를 가끔 들여다봐야 한다.
RAGAS 도입 + 한계 + 유형별 도구 분담
평가 LLM이 채점에서 일관성 있는 점수를 못 주는 문제(소형 모델은 "0.7 천장"에 갇히고 gemma3는 변동이 크다)를 풀기 위해 RAGAS 프레임워크를 도입했다.
RAGAS의 매력은 방법론이 더 정교하다는 것:
- Faithfulness: 답변을 문장별로 분해해 각 문장이 컨텍스트에서 추론 가능한지 개별 판정 → Yes 비율
- AnswerRelevancy: 답변에서 질문을 역생성(3회)해 원래 질문과 코사인 유사도 비교
근데 도입하고 보니 B·C유형이 전부 0점으로 나왔다. 원인은 RAGAS의 설계 가정에 있었다. AnswerRelevancy는 "답변 → 역질문 생성" 구조인데, 거부 응답("해당 내용은 영상에서 확인되지 않습니다")에는 어떤 질문에 대한 거부인지 정보가 없어서 역생성이 의미 있는 질문을 만들지 못했다.
RAGAS 버그가 아니라 "답변이 있는 상황을 전제" 로 설계됐기 때문. 결론은 유형별로 평가 도구를 다르게 쓰는 것:
| 유형 | 평가 도구 |
|---|---|
| A (근거 기반) | RAGAS Faithfulness, AnswerRelevancy, ContextPrecision |
| B (모호) | LLM-as-Judge (context 포함 answer_relevance, 보정 채점) |
| C (답변 불가) | 패턴 매칭 (rejection_rate, "확인되지 않습니다" 류) |
이 분리가 자리 잡으니 평가 점수가 한결 안정됐다. 하나의 만능 평가 지표를 찾기보다, 유형별로 적합한 도구를 분담시키는 것이 답이었다.
RAGAS의 구조적 한계와 유형별 평가 도구 분담은 4편 에피소드 3에서 더 자세히 풀었다.
24분 영상을 1분 10초에 처리하기 — 병렬화
24분짜리 영상을 처음 올렸을 때 처리 시간이 15분 8초 였다. 재생 시간보다 긴 처리 시간은 실서비스에서 안 된다.
asyncio.gather + asyncio.Semaphore 조합으로 병렬화를 적용했더니 — 환경에 따라 효과가 크게 달랐다.
| 환경 | 병렬화 전 | 병렬화 후 | 개선 |
|---|---|---|---|
| 로컬 (CPU-bound) | 908초 | 861초 | 5.2% ↓ |
| 배포 (I/O-bound) | 238초 | 70초 | 70.6% ↓ |
같은 코드인데 환경별 ROI가 14배 차이 났다. 로컬에서는 STT(faster-whisper)와 비전(Ollama)이 같은 CPU/GPU 자원을 두고 경합해서 병렬 효과가 거의 없었고, 배포에서는 둘 다 원격 API 호출이라 병렬화가 무료 점심처럼 동작했다.
또 하나 흥미로운 발견 — 외부 gather보다 내부 Semaphore가 훨씬 효과적이었다.
| 병렬화 유형 | 절감 | 기여도 |
|---|---|---|
| STT ↔ 프레임 (gather) | 9초 | 5% |
| 프레임 분석 3개씩 (Semaphore) | 115초 | 69% |
| 세그먼트 저장 5개씩 (Semaphore) | 40초 | 24% |
작업 단위의 동시 호출(N개 프레임을 3개씩 동시에)이 파이프라인 단위 병렬화보다 임팩트가 컸다.
최종 성능: 24분 영상을 70초에 처리 → 20.6배 배속. 순수 로컬 대비 13배 개선.
환경별 ROI 차이와 작업 단위 동시성의 디테일은 5편 에피소드 3에서 자세히 분석했다.
동적 Threshold + LLM 리랭커
여기까지 와서도 못 푼 케이스가 있었다. 정답이 들어 있는 세그먼트가 threshold=0.5 바로 아래 에 위치해서 0건 검색되는 경우. 예: 한 질문의 정답 세그먼트 유사도 0.4618.
해결: Top-K + 최소 보장 패턴.
MIN_RESULTS = 2
all_results = supabase.rpc(MATCH_RPC, {...}).execute()
filtered = [r for r in all_results if r["similarity"] >= threshold]
if len(filtered) < MIN_RESULTS:
filtered = all_results[:MIN_RESULTS] # fallback
return filteredthreshold 이상으로 최소 품질 보장하되, 부족하면 강제로 상위 N개 포함. 정답이 threshold 바로 아래에 있던 케이스가 이걸로 복구됐다.
이어서 장편 영상(24분)에 LLM 리랭커를 붙여 봤다. 30개 후보를 fetch → LLM으로 5개 선별. A/B 테스트 결과:
| 지표 | Baseline (OFF) | Rerank (ON) | Δ |
|---|---|---|---|
| Answer Relevance (A/B) | 0.944 | 1.000 | +0.056 ✅ |
| Groundedness | 0.600 | 0.709 | +0.109 ✅ |
| Retrieval Precision | 0.527 | 0.400 | -0.127 ⚠ |
| RAGAS Faithfulness | 0.841 | 0.861 | +0.020 ✅ |
흥미로운 패턴 — Retrieval Precision은 떨어졌는데 답변 기준 지표는 모두 올랐다. 리랭커가 임베딩 유사도가 낮은 후보 중에서도 실제 관련 있는 청크를 잘 골라낸 결과. 단일 지표(Precision)로 판정하면 손해 본 것처럼 보이지만, 답변 품질 종합으로는 이득 이라는 반직관적 결과.
단일 지표의 함정과 리랭커의 진짜 가치는 4편 에피소드 4에서 자세히 풀었다.
PROVIDER=deployment — 모듈별 최적 모델 혼합
집중 실험에서 발견한 "이론적 최적 조합"을 실제 코드로 가져오기 위한 작업.
기존 local/openai 2분법 아키텍처는 모듈별 최적 모델이 흩어져 있을 때 조합을 못 만든다.
| 모듈 | local 최적 | openai 최적 | 실제 최적 |
|---|---|---|---|
| STT | faster-whisper large-v3-turbo | whisper-1 (성능 낮음) | Groq whisper (동일 모델, 65배 빠름) |
| Vision | gemma3 (로컬 4B 제한) | gpt-4o (비용 높음) | Gemini 2.5 Flash (무료, 한국어 우수) |
| Embedding | bge-m3 ✅ | text-embedding-3-small ❌ | bge-m3 via HuggingFace (동일 모델) |
| Chat | llama3.1 (0.7 천장) | gpt-4o ✅ | GPT-4o ✅ |
| 평가 LLM | gemma3 (변동 큼) | gpt-4o ✅ | GPT-4o ✅ |
→ PROVIDER=deployment 신설. 기존 local·openai 분기는 한 줄도 변경하지 않고, if PROVIDER == "deployment":를 기존 분기 앞에 추가. 로컬 개발 환경 동작은 100% 보존.
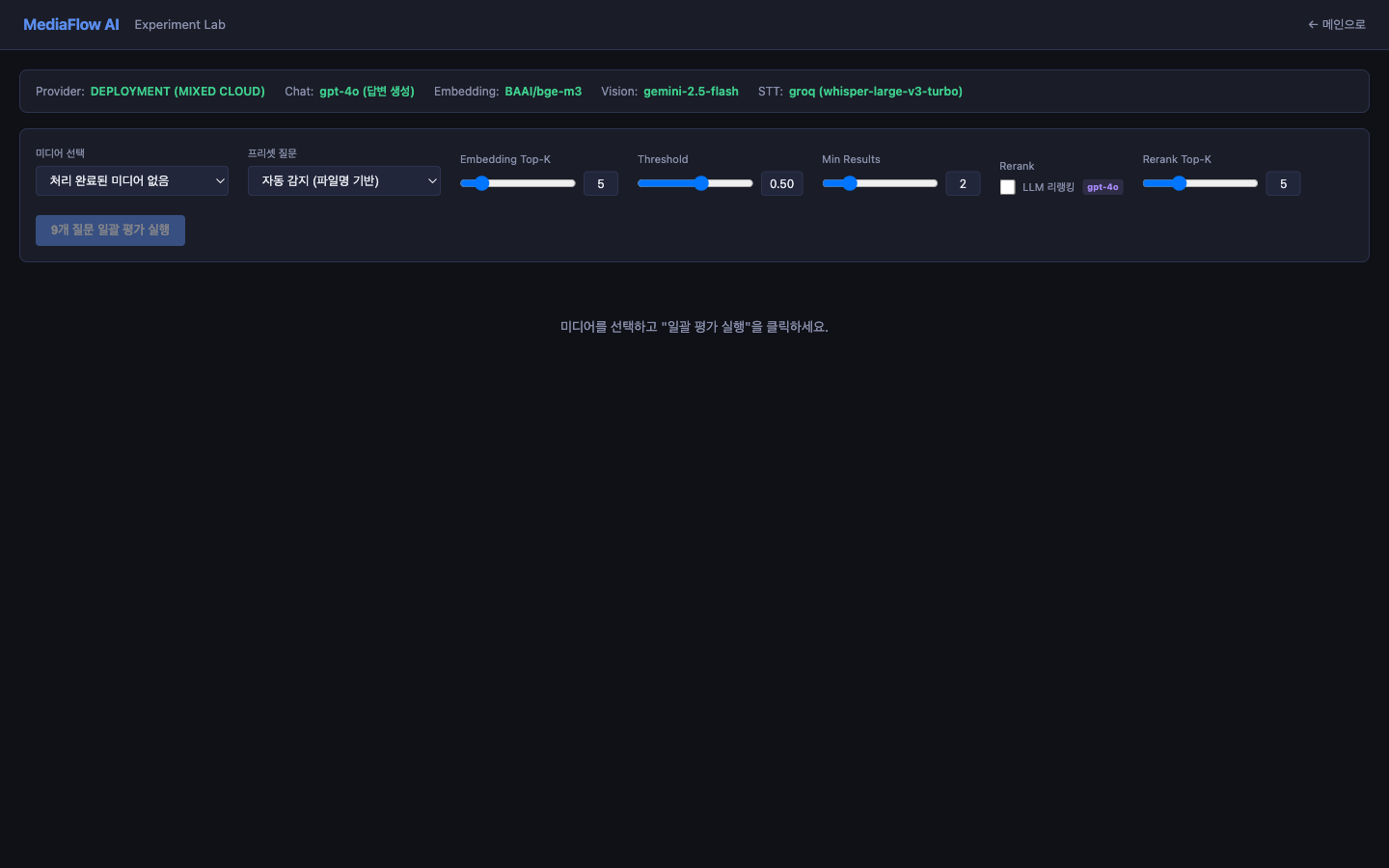
PROVIDER=deployment를 켜면 모듈별로 골라 쓴 모델 조합이 상단에 그대로 노출된다. "이론적 최적 조합"을 한 눈에 볼 수 있게 배너로 박아둔 결과.
배포 후 비용: 영상 10개 처리 시 ~$1.41/month (STT/Vision/Embedding은 모두 무료 티어, GPT-4o만 유료). 실험으로 확인한 "유료 가치"가 분명한 영역에만 비용을 쓰는 셈.
배포 자체에서도 트러블슈팅이 여러 건 있었는데, 그 중 AV1 코덱 문제(cv2 wheel의 플랫폼별 차이) 하나만 짧게 적자면 — 배포 후 비전 프레임 분석이 조용히 빠져 있는 증상으로 시작해, 원인을 추적해보니 cv2가 자기만의 FFmpeg을 번들링하고 있다는 사실에 도달했다. 같은 PyPI 패키지라도 macOS wheel과 Linux wheel의 내부 구성이 달랐다.
"로컬에선 됐는데" 류의 함정 4가지(async/def, AV1 코덱, 병렬화 ROI, 호환 SDK)는 5편에서 묶어서 다뤘다.
정리하면서
이번 사이클로 박힌 감각.
-
약한 고리 하나가 파이프라인 전체를 무력화한다. 한국어 미지원 임베딩 / 한국어 미지원 비전 — 이런 것 하나만 끼어 있어도 다른 모든 강화가 의미 없어진다. 모델 선택은 가장 어려운 케이스에서 검증해야 한다.
-
변수 1개씩 격리한 반복 실험이 미신을 깨는 유일한 길. 집중 실험 10회를 거치니 "어떤 것이 진짜 효과 있는 변수인가"가 비로소 보였다. 1회 결과는 노이즈일 가능성이 높다.
-
이론적 최적 조합이 안 만들어지는 이유는 의외로 코드 아키텍처에 있다. 모듈별로 다른 프로바이더를 섞을 수 있어야 모델별 강점을 합칠 수 있다.
가장 큰 변화는 — "하나의 잘 동작하는 조합" 을 찾기보다 "여러 조합을 안전하게 비교할 수 있는 파이프라인" 을 만드는 게 진짜 일이라는 감각.
다음 편
여기까지가 RAG·멀티모달 시스템 구축의 종단 흐름이다. 다음 두 편은 두 사이클을 가로지르며 발견한 공통 패턴을 묶었다.
-
4편 — 지표는 올랐는데 체감은 나빠졌다 — RAG 평가의 역설 Vision 환각, 임베딩 분포, 올바른 거부가 0점인 평가 함수, 검색≠답변, LLM 비결정성 — 평가 체계가 품고 있는 5가지 역설.
-
5편 — 로컬에서는 됐는데요 — 배포 직전 한 달간 마주친 4가지 함정
async def가 서버를 멈추는 문제, AV1 코덱이 조용히 빠지는 cv2 wheel 차이, 병렬화 ROI가 환경별 14배 차이 나는 이유, "호환 API"의 응답 타입 함정.
프론트엔드 6년차 개발자가 PI Lab에서 AI 엔지니어링 8주 과정을 수료하며 정리한 기록입니다. 매일 Cursor·Claude로 바이브코딩하면서도 머신러닝 안쪽은 잘 몰랐던 개발자가, AI 시스템을 본격적으로 들여다본 회고입니다.